



















ComfyUI 是一个基于节点的图形用户界面(GUI),专门为 Stable Diffusion 设计。它通过将图像生成工作流程分解成不同的块(称为节点),用户可以通过链接这些节点来构建复杂的图像生成流程,从而实现精准的工作流定制和完善的可复现性。这种设计使得 ComfyUI 在图像生成方面具有显著的优点,能够模块化地处理稳定扩散算法,带来更高的灵活性和精确性。
要说 ComfyUI 首先要从Stability AI说起。一开始 Stability AI 发布开源第一个版本Stable Diffusion,但是由于WEB界面下集成多种工作流程与功能节点,对于新手使用确实是方便,但是对于专业开发与工作搭建工程师,却显得较为臃肿。ComfyUI 并不是由 Stability AI 团队开发的,而是由一位匿名开发者创建并维护为开源能让更多人能够自己自定义针对工作流创新与发展,基于ComfyUI构建一个新的方式,以便理解工作流与逻辑实现更好为开源创新发展。目前 ComfyUI 拥有一个社区维护的文档库,提供详细的使用指南和技术支持,帮助用户更好地掌握和使用这个工具。
这里先说Stable Diffusion。Stable Diffusion 是一种用于生成图像的特定类型的 AI 模型。这些图像的范围从照片级逼真(类似于您用相机拍摄的图像)到更风格化、更艺术化的表现形式(类似于专业艺术家的作品)。主要功能是根据文本描述创建图像,但它并不仅限于此。您还可以将其用于其他任务,例如修复、修复和根据文本提示生成图像到图像的转换。而且它不仅限于图像 – 您还可以使用此模型创建视频和动画。基础模型是 Stability AI 发布的官方版本。这些是您可以直接使用的基本模型。另一方面,自定义模型本质上是使用附加数据重新训练的基础模型。这种重新训练使它们能够生成特定风格或对象的图像。如果您想创建介于两个模型之间的风格,您可以轻松合并两个模型来实现这一点。
(可以参考如下图)视频来源(https://static.clipdrop.co/)
Stable Diffusion组成部分,它不只是一个大型的单一模型。相反,它由各种组件和模型组成,它们协作从文本生成图像。模型文件很大.ckpt,或者.safetensors从 HuggingFace 或 CivitAI 等存储库获取的文件。这些文件包含三个不同模型的权重:
CLIP– 将文本提示转换为 UNET 模型可以理解的压缩格式的模型
MODEL– 主要的稳定扩散模型,也称为 UNET。生成压缩图像
VAE– 将压缩图像解码为正常图像
CheckpointLoader
在默认的 ComfyUI 工作流中,CheckpointLoader 充当模型文件的表示。它允许用户选择要加载的检查点并显示三种不同的输出:MODEL、CLIP 和 VAE。

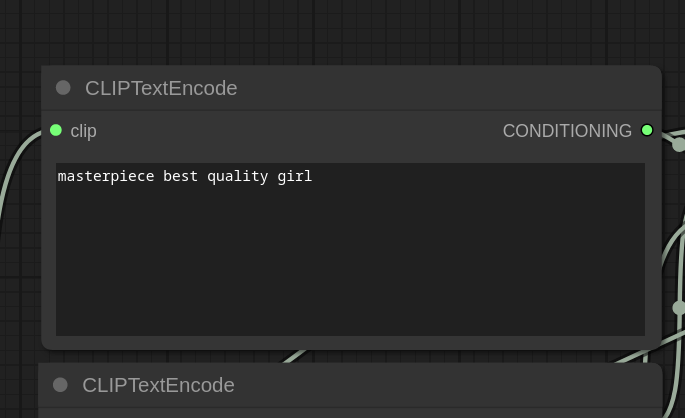
1. CLIP 模型
CLIP 模型连接到 CLIPTextEncode 节点。CLIP 充当文本编码器,将文本转换为主 MODEL 可以理解的格式。
2. Stable Diffusion MODEL(又名 UNET)
在Stable Diffusion中,图像生成涉及一个采样器,由 ComfyUI 中的采样器节点表示。采样器将主Stable Diffusion MODEL、CLIP 编码的正提示和负提示以及潜像作为输入。潜像是一个空图像,因为我们是从文本 (txt2img) 生成图像。
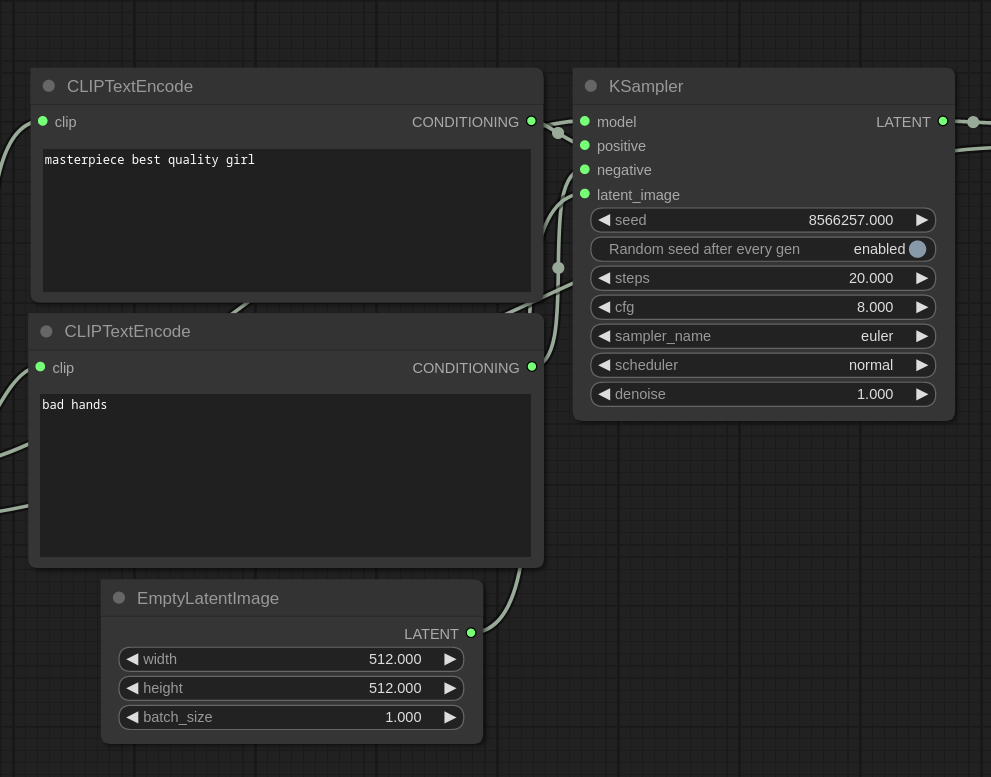
采样器为输入的潜像添加噪声,并使用主模型对其进行去噪。在编码提示的指导下,逐步去噪是稳定扩散生成图像的过程。
3.VAE模型
Stable Diffusion中使用的第三个模型是 VAE,负责将图像从潜在空间转换为像素空间。潜在空间是主模型理解的格式,而像素空间是图像查看器可识别的格式。
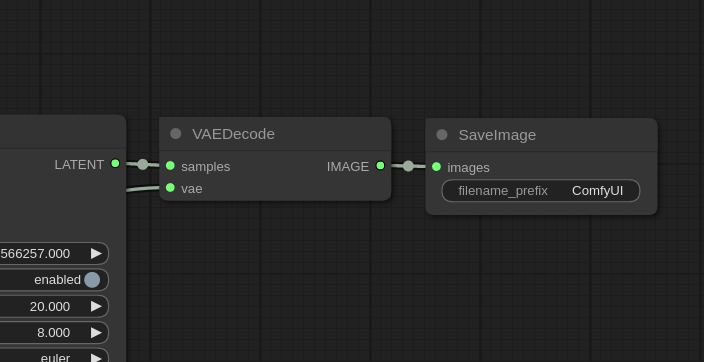
VAEDecode 节点将采样器中的潜像作为输入并输出常规图像。然后使用 SaveImage 节点将该图像保存为 PNG 文件。
以上就是,文生图逻辑,根据文本提示转换为 UNET 模型可以理解的压缩格式的模型文本编码,并通过节点将采样器将识别的文本编码通过 VAE,负责将图像从潜在空间转换为像素空间,并输出在图片预览保存器节点。整个流程如下:















